
TUNiBrain–Korean Morphological Analyzer

The next-gen Korean morphological analyzer
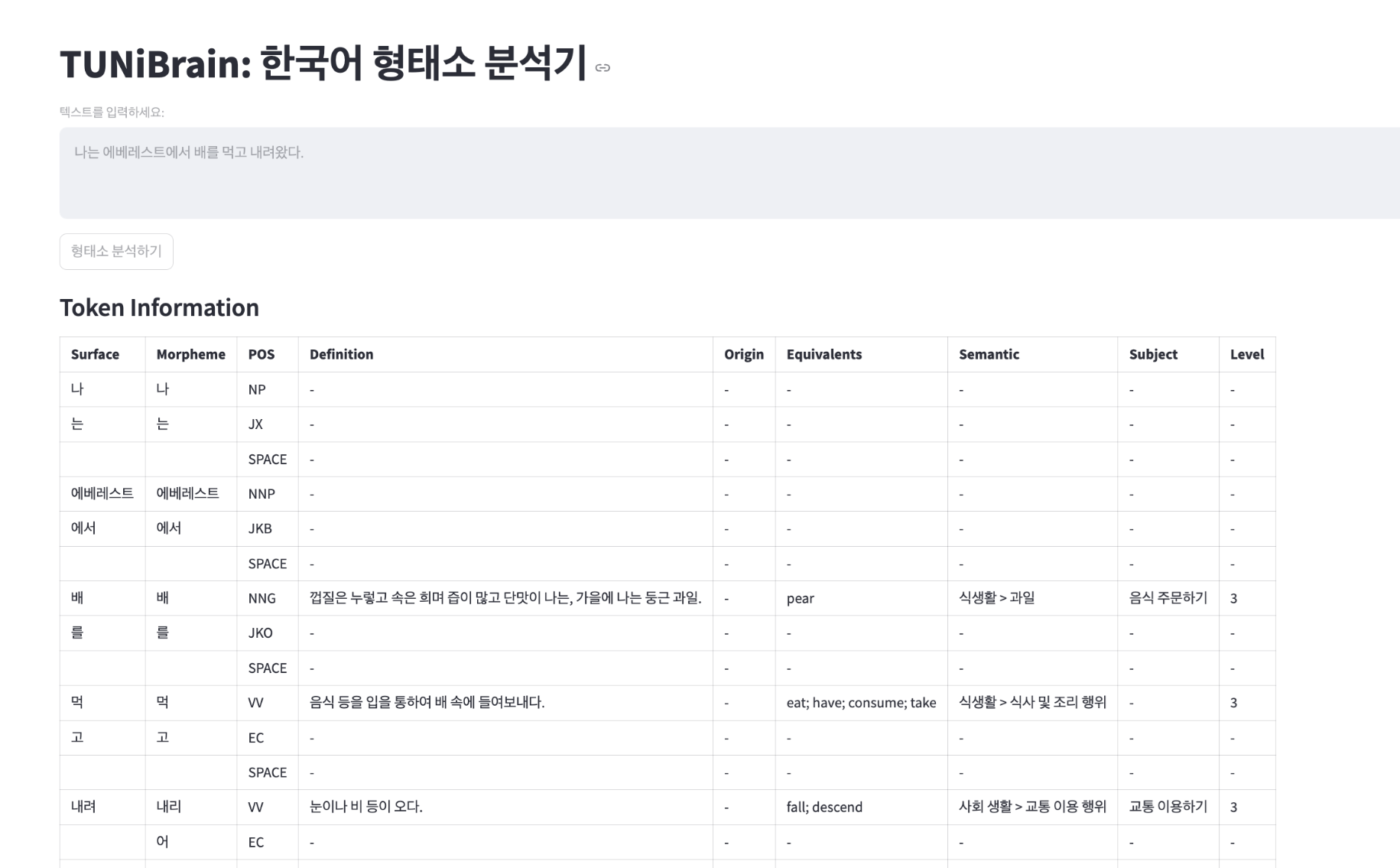
TUNiBrain–Korean Morphological Analyzer – Meaning-aware Korean language processing with deep learning and dictionaries
Summary: TUNiBrain is a hybrid Korean morphological analyzer combining deep learning and dictionary-based NLP to interpret meaning beyond tokenization. It detects proper nouns, disambiguates word senses, and provides definitions, senses, and translations for each token, enhancing accuracy in Korean NLP applications.
What it does
TUNiBrain integrates CRF-based MeCab parsing, Bi-LSTM proper noun detection, LESK and TF-IDF word-sense disambiguation, and a semantic dictionary (TUNiBank) to analyze Korean text. It outputs sense IDs, definitions, origins, and English equivalents for tokens, resolving ambiguities like homonyms and proper nouns.
Who it's for
It is designed for developers and researchers building Korean NLP systems, including chatbots, search engines, and language model pipelines requiring precise morphological and semantic analysis.
Why it matters
TUNiBrain addresses the limitations of tokenization-only analyzers by providing meaning-aware processing that distinguishes ambiguous words and proper nouns, improving the accuracy and usefulness of Korean language applications.