
TextLayer OCR

Turn scanned PDFs searchable while preserving forms
#Productivity
#Developer Tools
#Artificial Intelligence
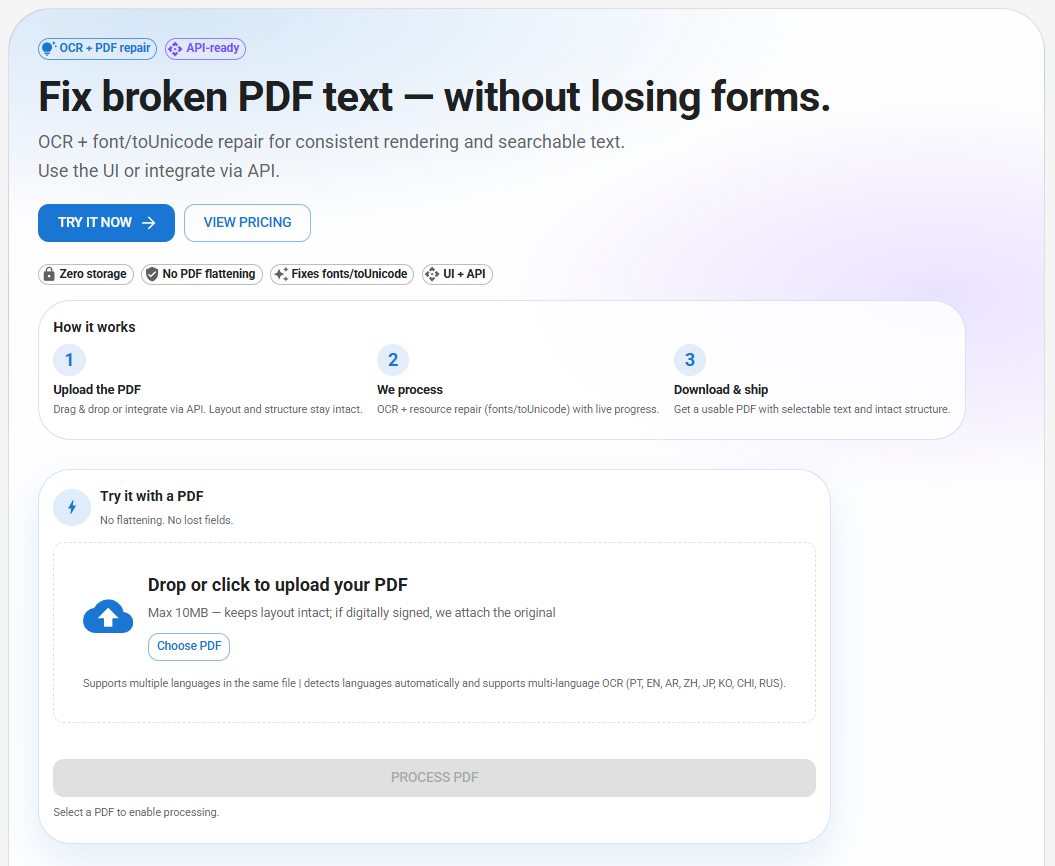
TextLayer OCR – Searchable scanned PDFs with form preservation
Summary: TextLayer OCR repairs PDF fonts and encoding errors while preserving AcroForm fields and widgets, enabling searchable and selectable text in scanned PDFs. It offers both a UI and API for automated processing without altering the original document structure.
What it does
It fixes corrupted or incomplete PDF fonts and encoding issues, runs OCR to make text searchable, and maintains all PDF form fields and metadata intact.
Who it's for
Ideal for users handling legal documents, contracts, forms, or any scanned PDFs requiring editable and searchable content.
Why it matters
It prevents OCR tools from breaking PDF forms and metadata by repairing font resources while preserving the document’s original structure.