
Subquadratic LLM Solution

Subquadratic LLM Solution
#Artificial Intelligence
#Physics
Subquadratic LLM Solution – Universal patch for VRAM efficiency in LLMs
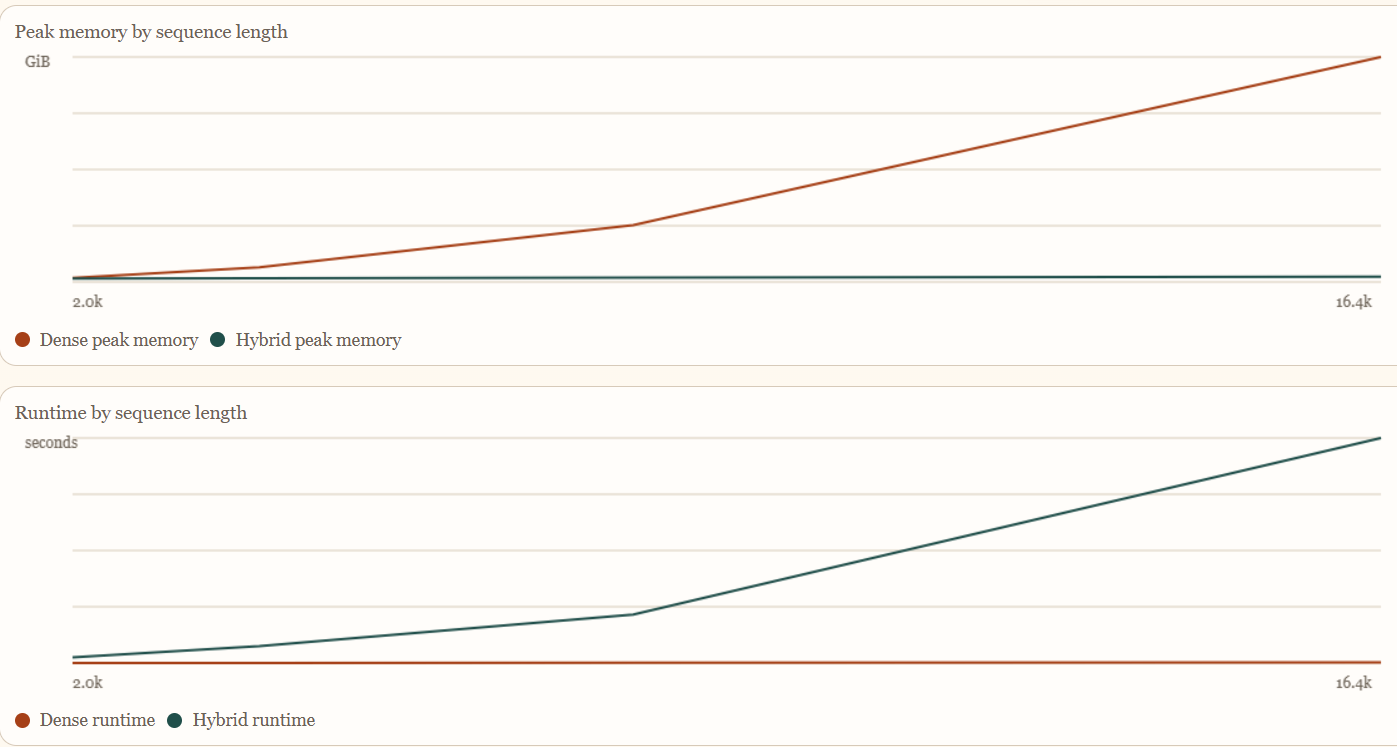
Summary: This solution addresses a flaw in classical computer architecture causing AI context window decoherence by enabling any LLM to use VRAM subquadratically without decoherence. It demonstrates improvements on a Mistral 7b model with a base versus patched comparison.
What it does
It applies a universal patch that reduces VRAM usage in LLMs to subquadratic levels while preventing context window decoherence.
Who it's for
Developers and researchers working with LLMs who need improved VRAM efficiency and context coherence.
Why it matters
It solves VRAM inefficiency and decoherence issues in LLMs, enabling more scalable and stable model usage.