
Start Benchmarking your LLMs.

Pick the best LLM. Compare costs and performance.
#Developer Tools
#Artificial Intelligence
#Tech
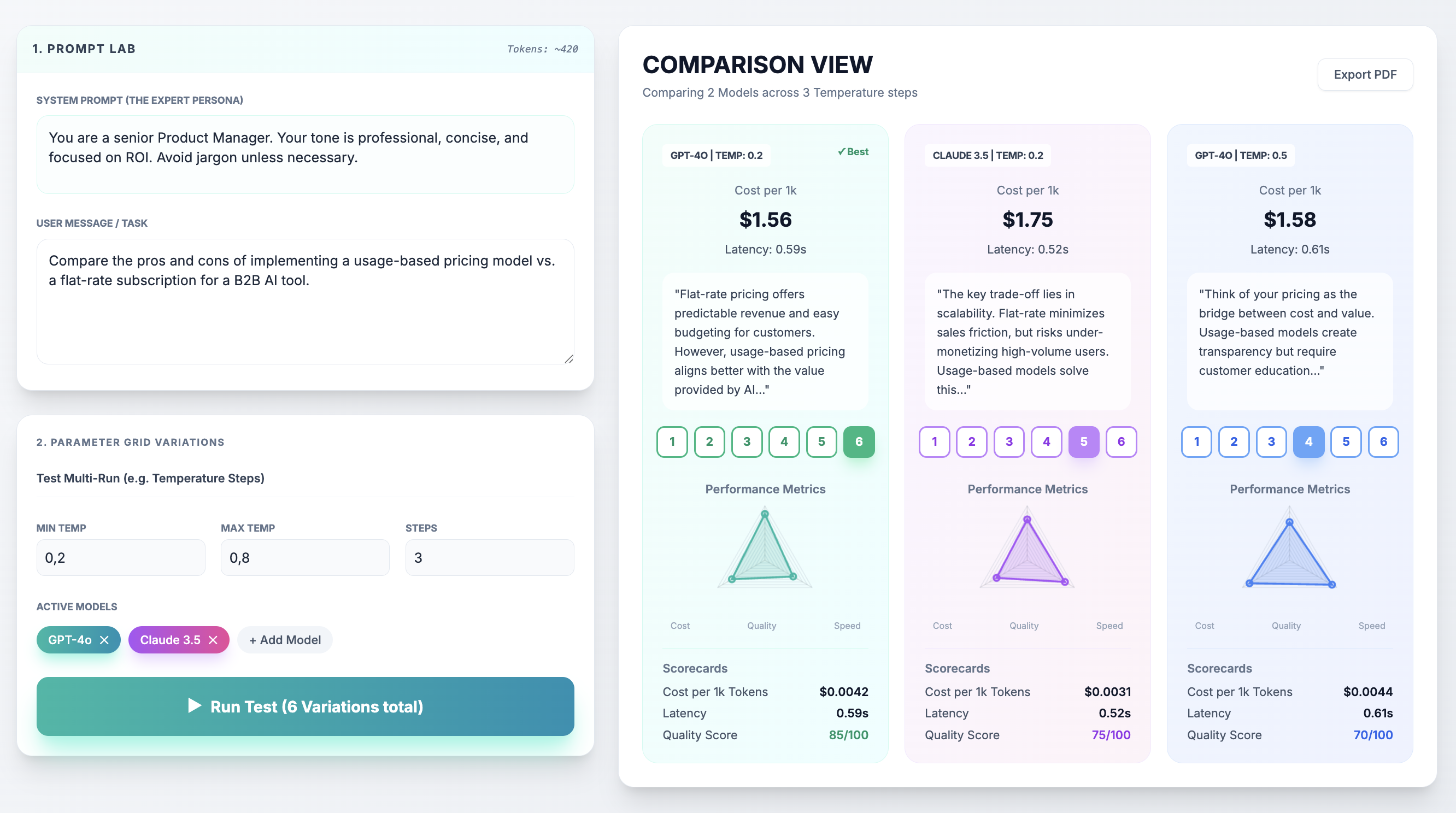
Start Benchmarking your LLMs. – Compare costs and performance across multiple AI models
Summary: This tool enables product managers to benchmark prompts across leading AI models by comparing costs and tracking performance with shared dashboards and team voting. It supports simultaneous multi-LLM prompt testing including GPT-4o, Claude 3.5 Sonnet, and Llama-3-70B.
What it does
It sends one prompt to multiple models at once, allowing users to compare outputs, costs, and performance through transparent feedback loops and shared dashboards.
Who it's for
Product managers seeking data-driven comparisons of AI models to inform decision-making and align engineering with product teams.
Why it matters
It replaces inefficient manual comparisons with a centralized system that provides objective, side-by-side benchmarking of LLMs.