
Raptor Data

Protect, cache and hot patch your LLM APIs. Built in Rust.
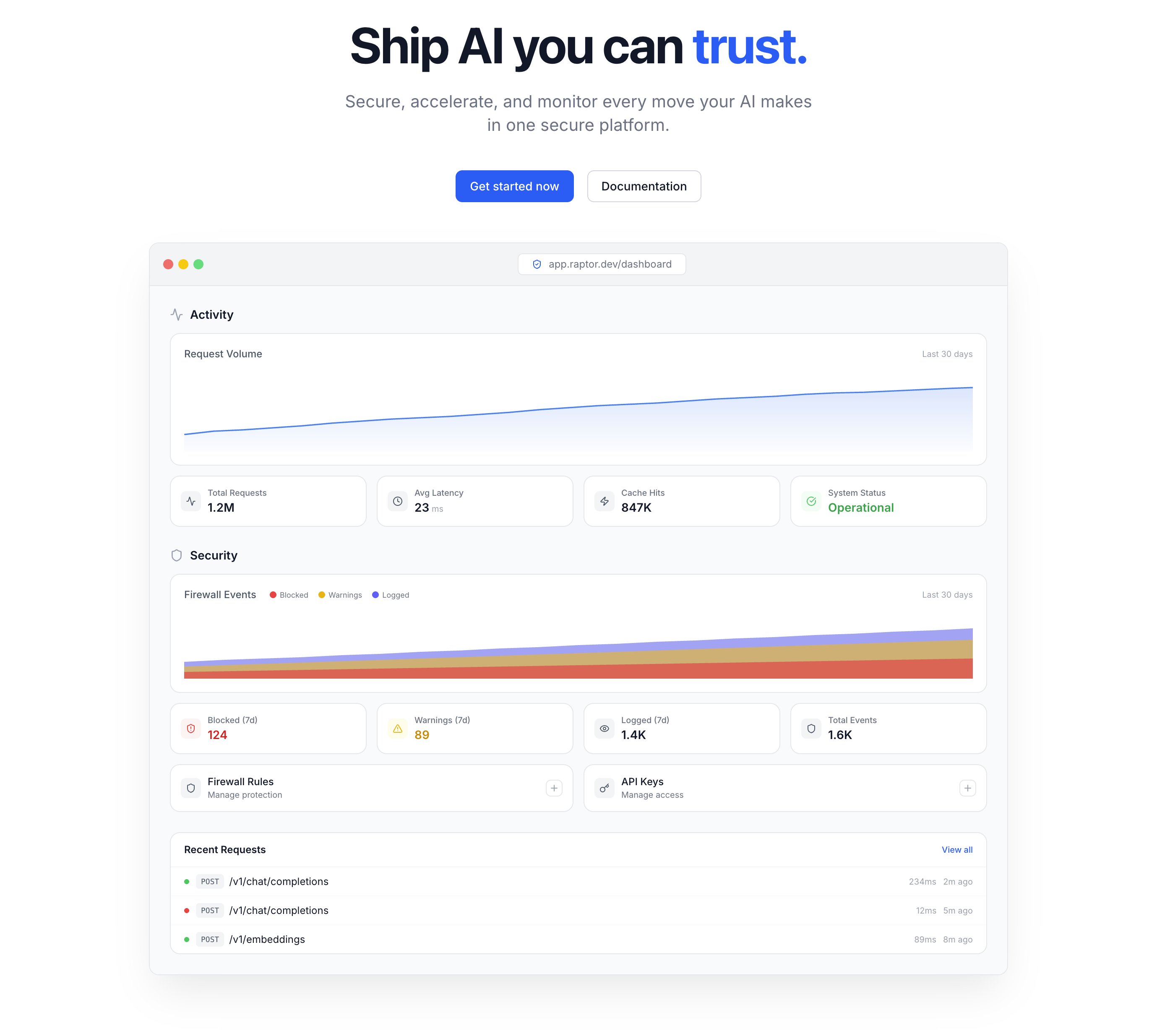
Raptor Data – Rust-powered AI gateway for caching, firewalling, and hot-patching LLM APIs
Summary: Raptor Data is a Rust-based AI gateway that reduces latency and costs by semantic caching, blocks prompt injections using intent-based firewalling, and enables hot-patching of LLM responses without redeployment. It supports OpenAI-compatible APIs with minimal overhead and provides observability through a unified dashboard.
What it does
Raptor acts as a proxy between your app and LLM provider, applying semantic caching to serve similar queries from cache in under 10ms, blocking malicious prompt injections by intent rather than keywords, and allowing instant hot-patching of incorrect AI responses without redeploying. It also offers full streaming support and request tracing.
Who it's for
Developers and teams using OpenAI, Anthropic, or compatible LLM APIs who want to reduce API costs, improve security against prompt injections, and quickly fix hallucinations in production.
Why it matters
It addresses redundant LLM calls and prompt injection vulnerabilities while enabling rapid fixes to AI errors, improving efficiency, security, and maintainability of LLM integrations.