
Qwen3-TTS

Voice design, cloning & 97ms streaming
#Open Source
#Artificial Intelligence
#Audio
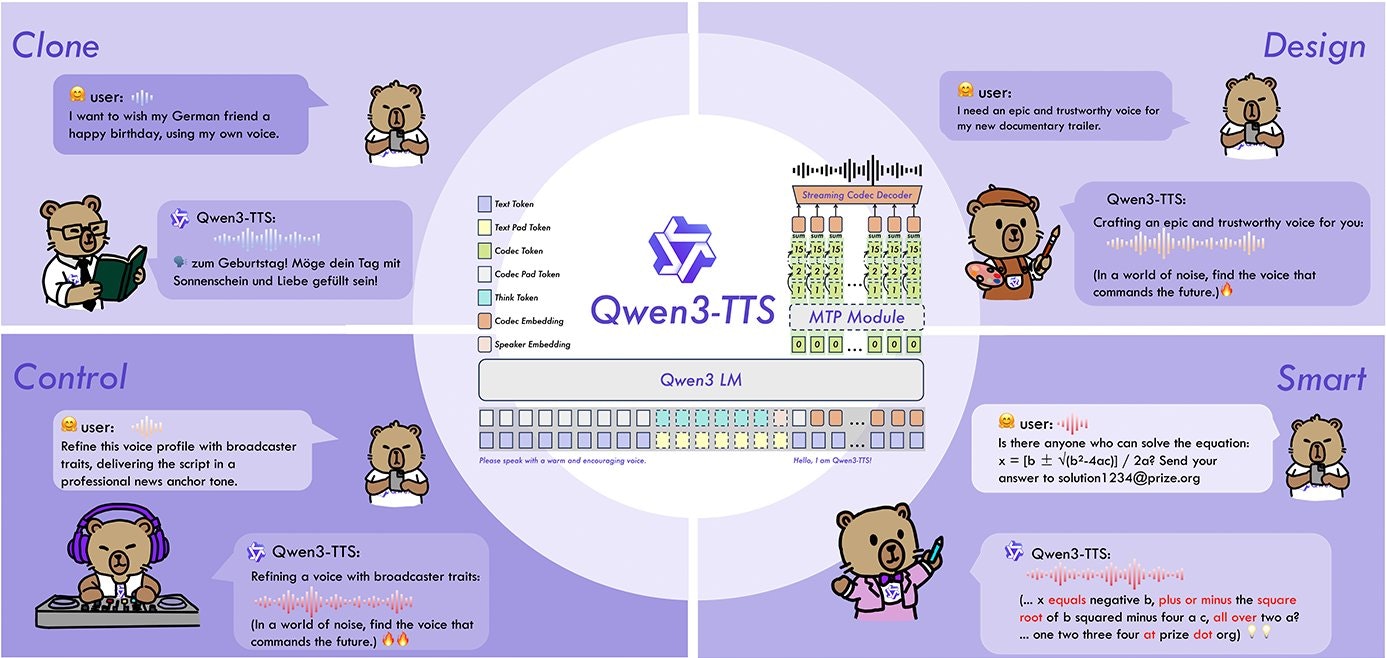
Qwen3-TTS – Multilingual low-latency speech synthesis with voice cloning
Summary: Qwen3-TTS is an open-source family of speech models (0.6B & 1.7B) supporting 10 languages, featuring prompt-based voice design, 3-second zero-shot voice cloning, and 97ms streaming latency. It uses a 12Hz tokenizer to compress speech efficiently without losing detail.
What it does
It generates high-quality speech with creative voice control by describing personas and enables fast, low-latency streaming through efficient tokenization.
Who it's for
Developers building voice applications requiring multilingual TTS with voice cloning and minimal latency.
Why it matters
It combines state-of-the-art quality, speed, and voice customization in an open-source TTS solution, improving real-time speech synthesis.