
OptiLLM

Intelligent LLM Cost Optimization Platform
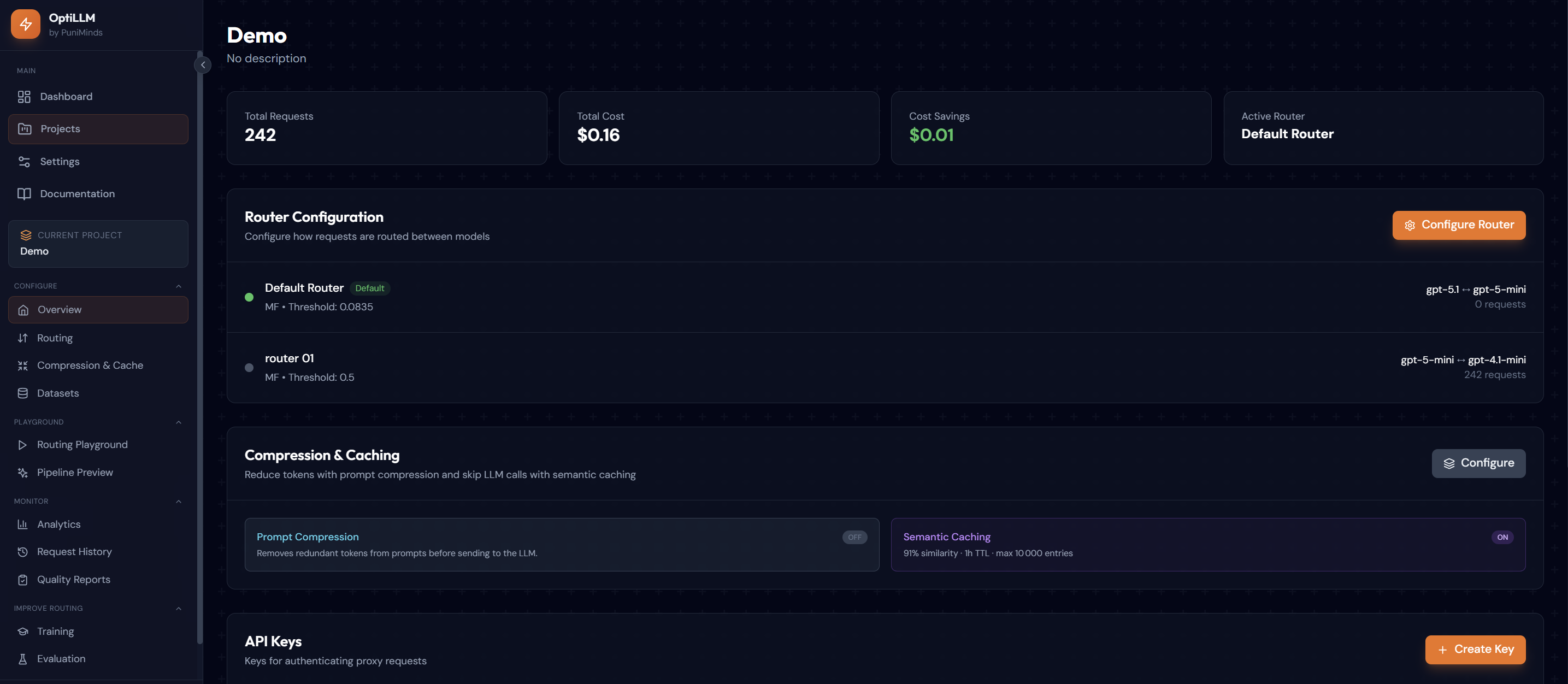
OptiLLM – Intelligent LLM Cost Optimization Platform
Summary: OptiLLM reduces LLM API costs by over 50% by routing prompts to the cheapest capable model, compressing tokens, and caching similar queries. It operates as a drop-in OpenAI-compatible proxy with built-in evaluation tools, analytics, and custom router training to optimize cost-quality balance continuously.
What it does
OptiLLM uses ML classifiers to route prompts to cost-effective models, applies token compression with LLMLingua-2, and caches semantically similar queries via FAISS vector search to lower expenses.
Who it's for
Developers and teams using LLMs who want to reduce API inference costs without modifying their existing code.
Why it matters
It addresses high LLM API costs by optimizing model selection and query handling to maintain quality while cutting expenses.