
Olmo Hybrid

7B open model mixing transformers and linear RNNs
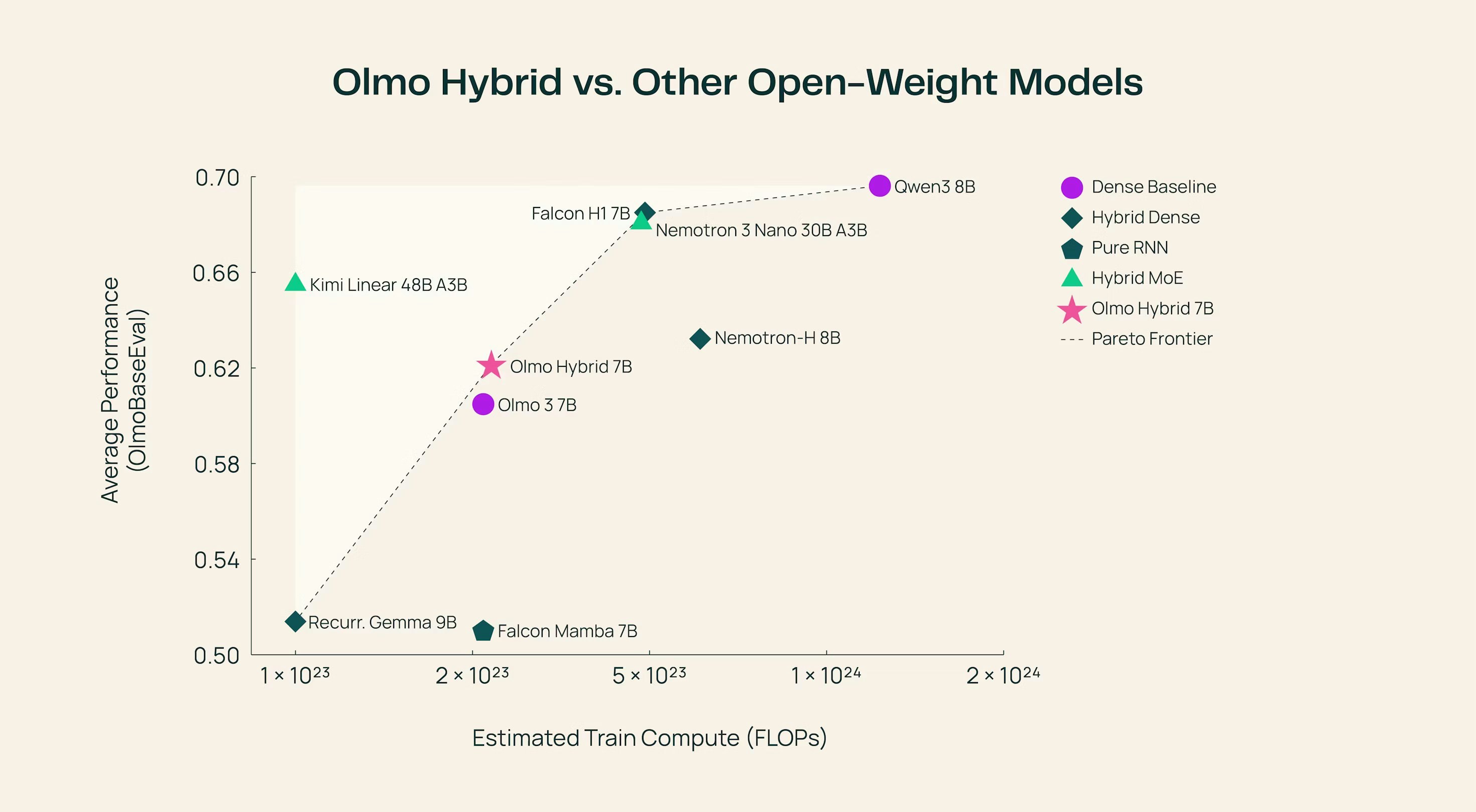
Olmo Hybrid – 7B open model combining transformers and linear RNNs
Summary: Olmo Hybrid is a 7B open model integrating transformer attention with linear RNN layers in a 3:1 ratio, matching Olmo 3’s accuracy on MMLU using 49% fewer tokens. It trains at the same speed and size as Olmo 3 while improving long-context evaluations.
What it does
It combines Gated DeltaNet linear RNN layers with transformer attention to optimize token efficiency and accuracy. The model’s weights are available on Hugging Face and can run fully locally in browsers via WebGPU.
Who it's for
Researchers and developers needing an efficient 7B model with improved long-context performance and open access to weights.
Why it matters
It reduces training data requirements by nearly half while maintaining accuracy and enabling local browser execution.