
Molmo 2

SOTA video understanding, pointing, and tracking VLM
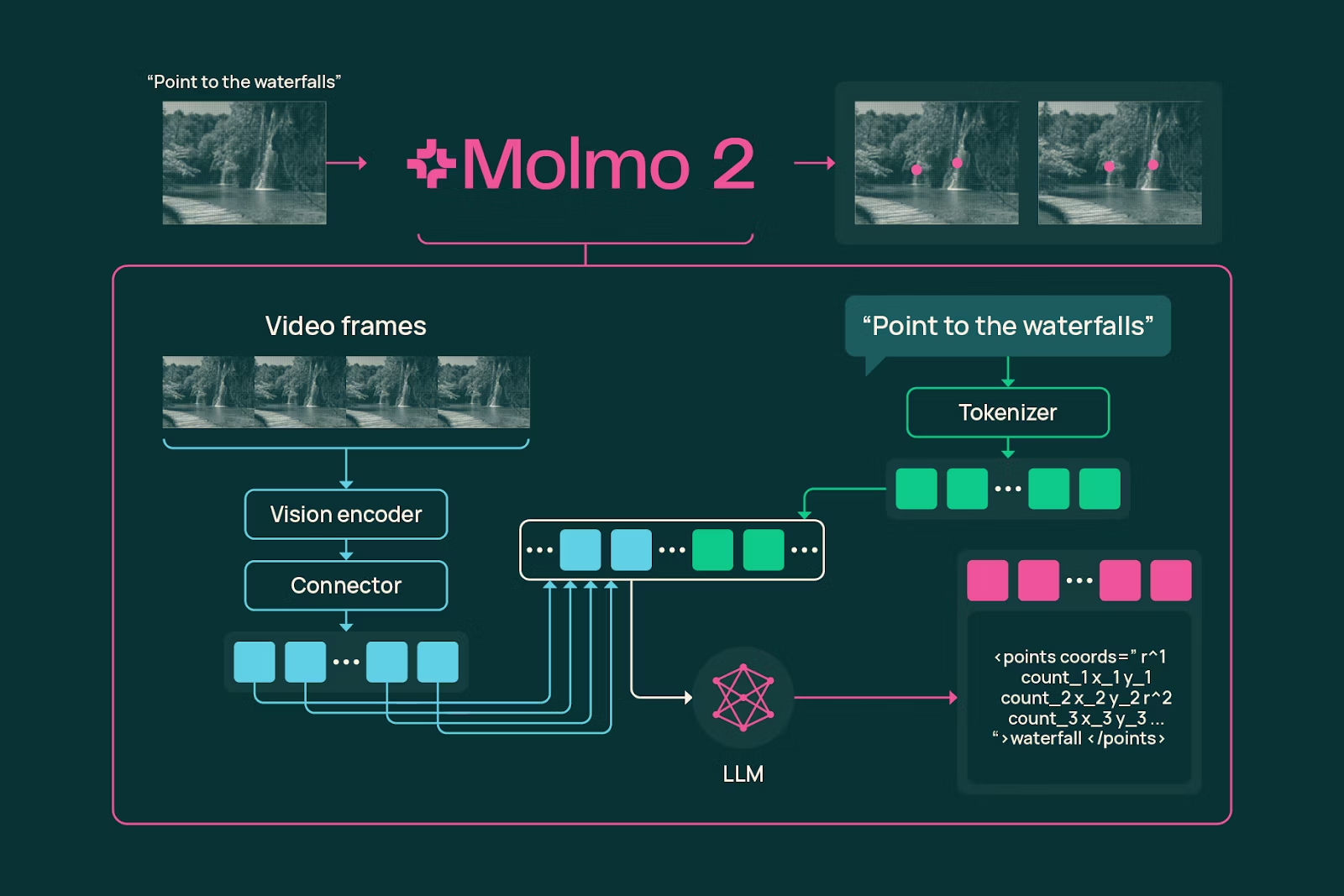
Molmo 2 – Advanced video understanding with spatial and temporal pointing
Summary: Molmo 2 is a vision-language model suite with open weights, training data, and code that analyzes videos and multiple images simultaneously, providing precise timestamps and spatial coordinates for events. It supports detailed video tracking and outperforms Gemini 3 Pro while using significantly less training data than Meta’s PerceptionLM.
What it does
Molmo 2 processes videos and images to deliver text summaries with exact timestamps and coordinates, enabling event pointing and tracking across space and time.
Who it's for
It is designed for users needing detailed video analysis and tracking with open-source vision-language models.
Why it matters
It improves video tracking accuracy and efficiency by providing precise spatiotemporal event localization using less training data than comparable models.