
Gemini 3.1 Flash-Lite

The fastest Gemini model.
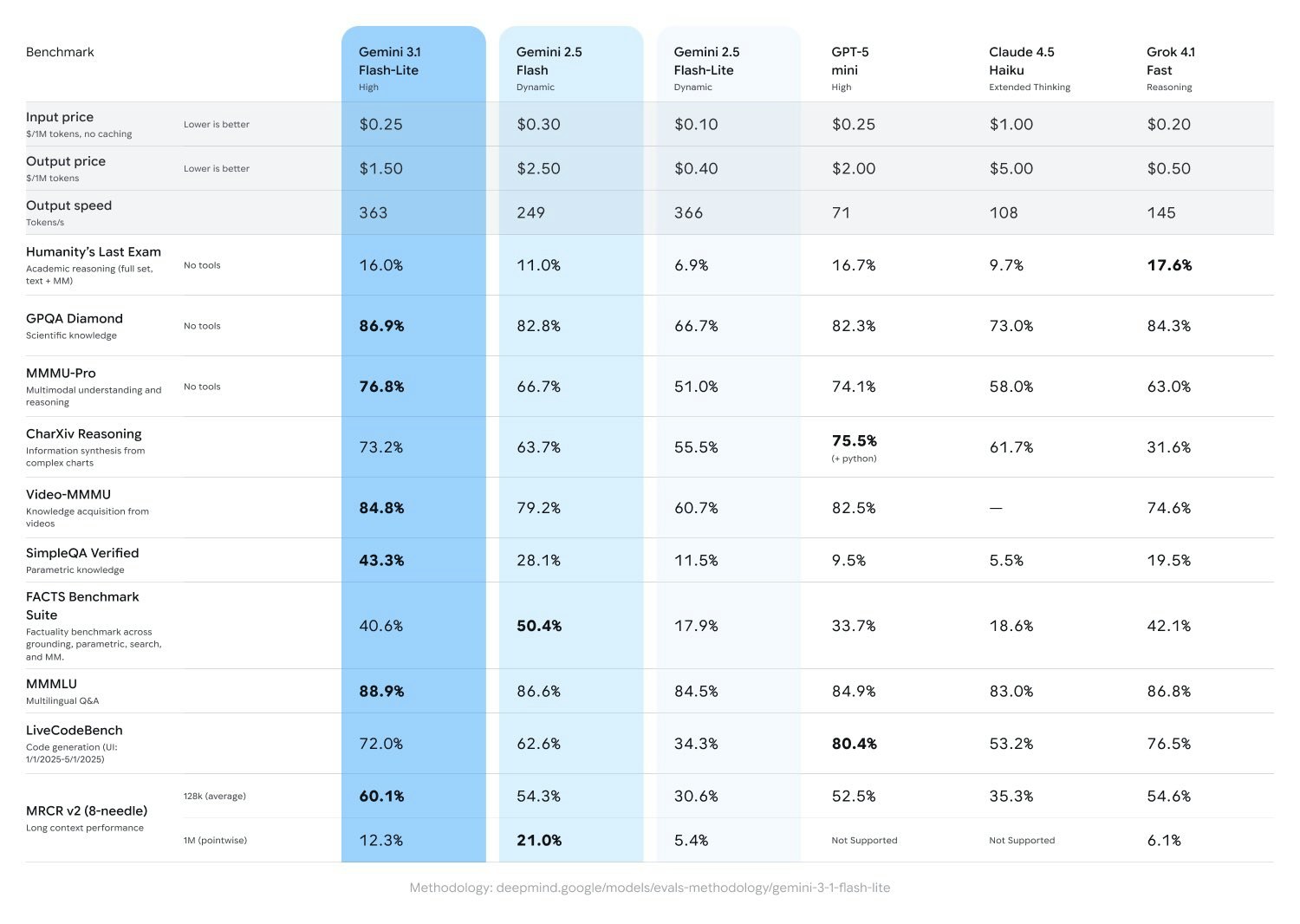
Gemini 3.1 Flash-Lite – High-performance, cost-efficient AI model for scalable workflows
Summary: Gemini 3.1 Flash-Lite delivers faster and more efficient performance than its predecessor 2.5 Flash while remaining the most affordable option in the Gemini family. It supports high-volume tasks, agentic pipelines, and structured outputs, making it suitable for large-scale AI applications without sacrificing key features.
What it does
It handles translation, transcription, classification, document processing, and summarization at scale with a 1M token context window, batch API, caching, function calling, and search grounding. It supports lightweight agentic pipelines with structured JSON output and includes thinking mode for reasoning before replies.
Who it's for
Developers and teams running high-volume AI content pipelines, support automation, data extraction, and multi-agent systems who need a balance between cost and capability.
Why it matters
It challenges the traditional tradeoff between speed, quality, and cost by outperforming previous full models in key tasks while offering a full production API feature set at a lower price point.