
Compress By Light Reach

AI is a commodity. Your bill should reflect that.
#Productivity
#Developer Tools
#Artificial Intelligence
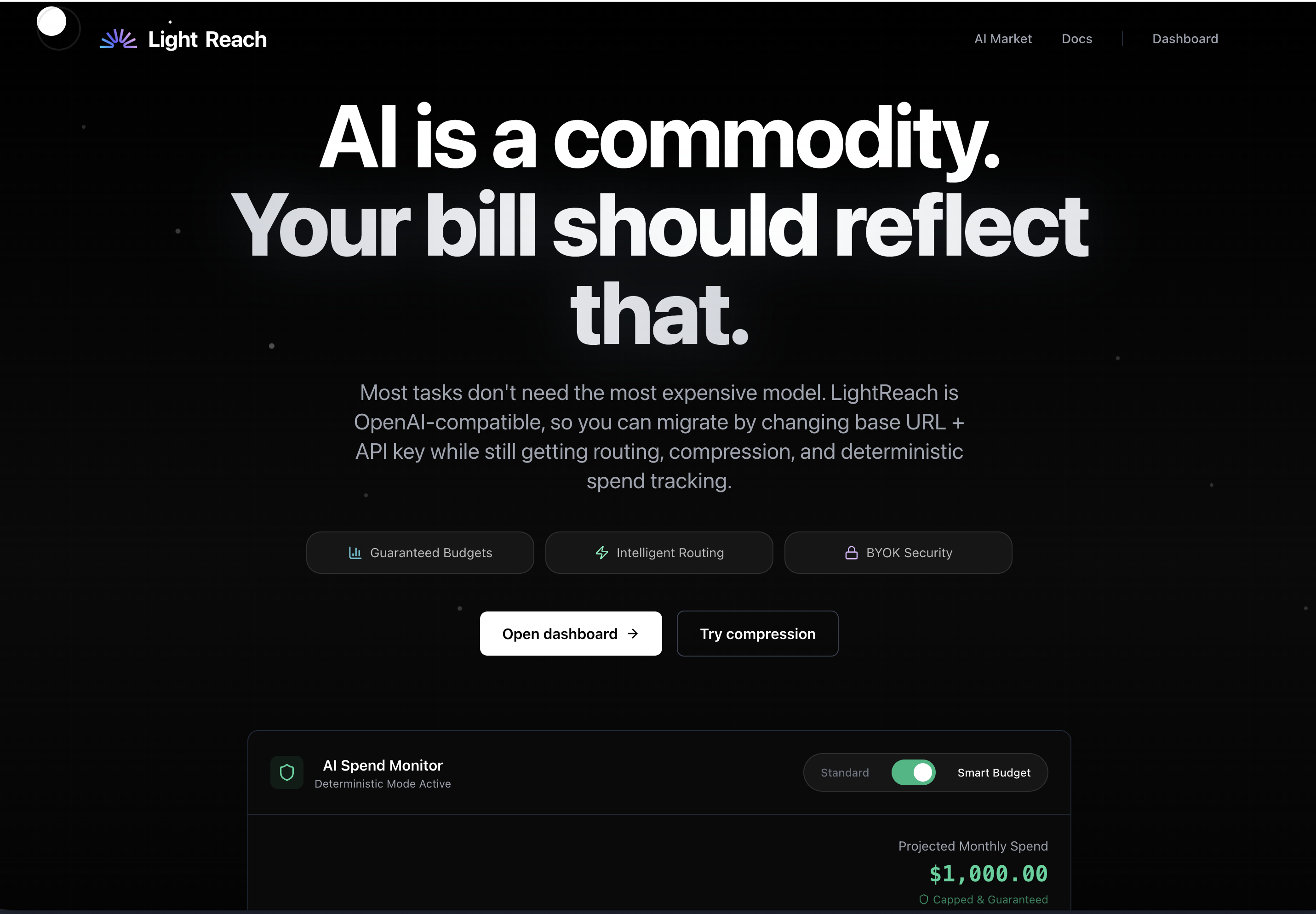
Compress By Light Reach – Reducing LLM costs with prompt compression and model routing
Summary: Compress By Light Reach lowers large language model (LLM) expenses by combining lossless prompt compression with intelligent routing to the most cost-effective model that meets quality targets. It operates via an OpenAI-compatible API and provides teams with insights into savings, budgets, and usage.
What it does
It compresses repeated prompt context and selects the cheapest suitable model using quality controls, optimizing LLM request costs through an OpenAI-compatible API.
Who it's for
Teams and organizations seeking to manage and reduce AI costs across features and usage.
Why it matters
It addresses high LLM spending by making usage more visible, controllable, and efficient through compression and model selection.