
Baldur KSL

Run 35B AI models 185% faster on your own GPUs
#Software Engineering
#Artificial Intelligence
#Tech
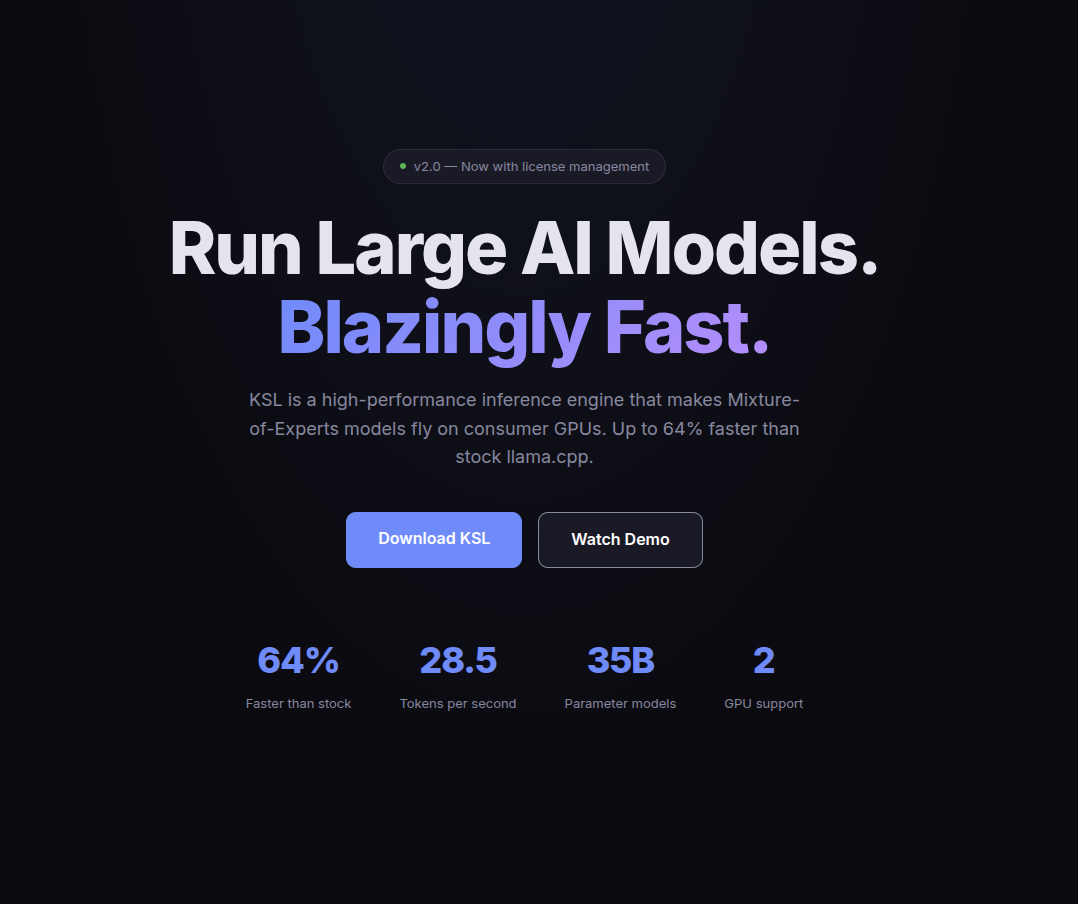
Baldur KSL – High-performance inference engine for faster AI model execution
Summary: Baldur KSL accelerates Mixture-of-Experts AI language models by 185% on consumer NVIDIA GPUs using proprietary optimizations, enabling faster local inference of 35B parameter models without relying on cloud services.
What it does
It optimizes AI language model inference to run significantly faster on gaming GPUs by leveraging a proprietary engine tailored for Mixture-of-Experts architectures.
Who it's for
Users who want to run large AI models locally on consumer NVIDIA GPUs without cloud dependency or latency.
Why it matters
It reduces inference time and avoids cloud costs and privacy concerns by enabling efficient local execution of large AI models.