
Antijection

Stop malicious prompts before they reach your AI
#API
#Artificial Intelligence
#Security
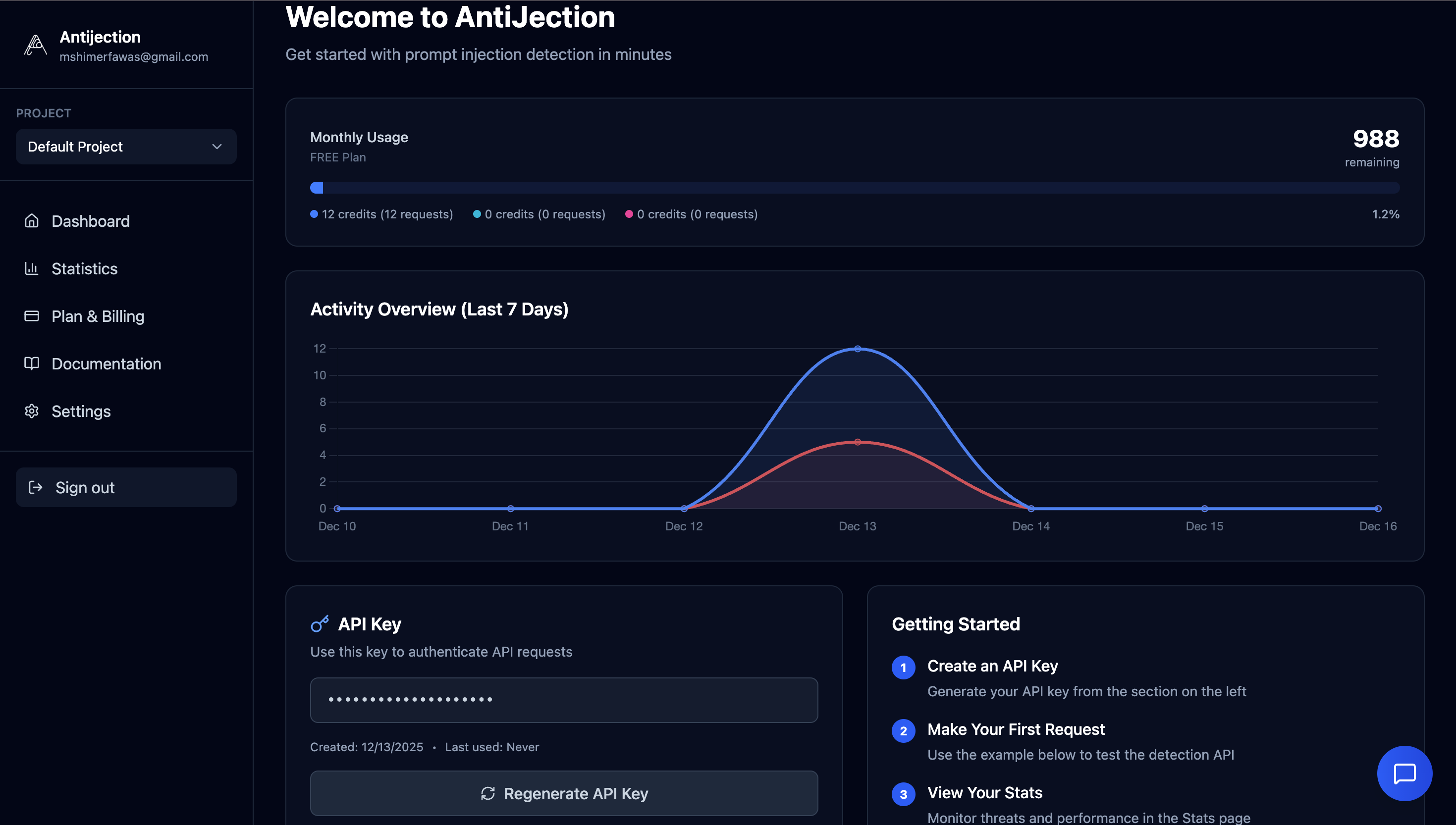
Antijection – Stop malicious prompts before they reach your AI
Summary: Antijection protects AI systems by detecting and blocking prompt injection, jailbreaks, and malicious inputs before they reach large language models (LLMs), preventing data leaks and manipulation.
What it does
It inspects every prompt as a pre-screening layer to identify and block risky or malicious intent targeting LLMs.
Who it's for
Teams and developers integrating LLMs who need to safeguard their AI applications from prompt-level attacks.
Why it matters
It prevents prompt-based attacks that can bypass guardrails, leak data, or manipulate AI outputs.